洛瓦兹局部引理
给定一个坏事件的集合 满足 ,我们希望研究在满足怎样的条件下所有坏事件都不发生的概率非零。简单地应用 union bound,我们知道 因此,如果 ,那么就有 。显然这只是一个充分条件,并且我们能够想象出对于某些情况,这个条件是非常松的。我们考虑以下两种情况:
- 当所有的事件都是互斥的时候,我们知道,union bound 是紧的。在这种情况下,这些事件的相关性很大;
- 当所有事件都是相互独立的,我们有 ,也就是总有非零概率使得所有坏事件都不发生。这说明 union bound 在事件独立的场合离真实情况非常的远。
经过上述的讨论,很自然地我们想知道有没有一个推广版本的 union bound,能够利用到事件之间的相关性。今天我们将介绍著名的洛瓦兹局部引理(Lovász local lemma)。在这之前,我们先引入依赖图(dependency graph)来刻画事件之间的依赖关系。固定一个坏事件的集合 。我们称无向图 为 的依赖图,当且仅当其满足下面这些条件:
在依赖图的定义中,如果 与 有边,我们不要求 与 是相关的。因此,事件集合 可能会有很多个不一样的依赖图。
- 每个顶点 对应于事件 ;
- 对于任意的, 事件 独立于
令 是依赖图 的最大度数。直观上来说,越小的 反映了事件之间的相关性越低。例如,当所有的事件都是互斥的时候, 一定是一个完全图。而当所有的事件都是相互独立的时候,边集 可以是空集。
Theorem 1 (洛瓦兹局部引理) 假设对于任意 ,存在某个实数 使得 。如果 ,那么 。
我们把洛瓦兹局部“引理”写作一个“定理”。定理里面的 是自然对数。
这两个界离我们上面讨论的实际情况还有一些常数上的差距。实际上,洛瓦兹局部引理能达到的最优的界被称为 Shearer 界(Shearer (1985) )。在 Shearer 界给出的条件下,洛瓦兹局部引理可以完全的推广独立和互斥的情况。
Shearer, James B. 1985. “On a Problem of Spencer.” Combinatorica 5: 241–45.
根据该引理,我们可以得出当事件互斥的时候,如果有 ,则坏事件都不发生的概率非零;而当事件相互独立的时候,如果 ,坏事件都不发生的概率非零。这两个界说明洛瓦兹局部引理确实能反映出这些事件之间的独立性。
Example 1 我们之前曾经讲过 Ramsey 数 指的是对于包含 个顶点的完全图 ,存在一个边的染色方案,使得其中任意的 个顶点构成的完全子图 都不是单色的。对于每一个大小为 的顶点集合 ,我们定义事件 为 “ 的导出子图 是单色的”。使用 union bound,我们知道当 时 因此我们有 。接下来我们使用洛瓦兹局部引理改进这个结果。
我们先构造依赖图,其中 和 相邻当且仅当 。那么 。根据洛瓦兹局部引理,当 时,存在一个染色的方案使得 不包含单色的大小为 的完全子图 。因此我们得到关于Ramsey数的一个更好的下界
我们称公式 为 -合取范式,当且仅当如果每一个子句 都包含了正好 个文字(literals)。合取范式 的度数为 指的是每一个变量最多出现在 个子句中。
Example 2 (k-可满足性问题(-SAT)) 给定一个度数为 的 -合取范式(-CNF),我们称一个合取范式 是可满足的,当且仅当存在一组变量上的赋值使得所有的子句都被满足。
我们可以使用洛瓦兹局部引理来给出合取范式可满足性的一个充分条件。首先,我们对于每个变量从集合 上均匀地赋值并且定义坏事件 为子句 在给定的变量赋值上不满足。那么我们有 。构造依赖图 为 当且仅当 和 有共用变量()。由于每个子句 都包含 个变量并且其中每个变量最多出现在 个子句中(注意 也被统计在内),我们有这个依赖图的最大度 。根据洛瓦兹局部引理,当 时, 有非零的概率存在一组变量上的赋值使得所有子句都被成立,也即 在该条件可满足。
Example 3 (独立集) 给定一个最大度为 的图 。设 。将 任意划分为 个部分 并且每个顶点集合 的大小不小于 ,也即。我们想说明总是可以从每一个集合 中选取一个顶点 ,使得 构成了一个独立集。
不失一般性,我们可以认为 的大小是 。否则我们可以对大小超过 的集合删掉一些点。如果我们能够从剩下的集合中选出特定大小的独立集,那么在原问题上也至少存在相应大小的独立集。对于每一个 ,我们从每一个集合中均匀随机地选点。对于图中的每一条边 ,我们定义坏事件 为“和都被选了出来”。那么。在该概率空间下,我们可以构造一个依赖图满足 当且仅当对于边 , 和 至少有一个出现在 或者 所在的分划中。因此,。根据洛瓦兹局部引理,由于 , 因此存在非 的概率使得选出的顶点构成原图中的一个独立集。
非对称洛瓦兹局部引理
注意到在更一般的情况下,坏事件发生的概率 可以是完全不一样的。因此,在 Theorem 1 中对于每个坏事件使用一个统一的上界显然不是最好的选择。我们接下来引入一个非对称版本的洛瓦兹局部引理。
Theorem 2 (非对称洛瓦兹局部引理) 如果存在一个函数 使得 ,那么 。
在证明 Theorem 2 之前,我们首先展示 Theorem 1 是该非对称版本的一个特例。我们令 ,那么 因此,应用引理 Theorem 2,条件 就能推出 。
Proof (Theorem 2 的证明). 对于任意顶点集合 ,令 。我们断言,对于所有 ,。一旦该断言成立,那么我们就得出 因此我们只需要证明,“对于所有 , ”。接下来,我们对 的大小使用归纳法进行证明:
当 时,我们的断言自然地成立。当集合 非空时,我们对集合中的事件按照是否与 在依赖图中相邻划分为 和 。令 为 中所有 的邻居构成的集合。如果 ,那么所有 中的事件都和 独立。因此, 如果 非空,不失一般性,我们令 。那么 由于 和 是独立的 根据归纳假设,我们有 因此,
Example 4 (非对称Ramsey数) 非对称Ramsey数 指的是存在对 的边的染色方案(颜色为蓝色或红色),使得既不包含一个蓝色的 也不包含一个红色的 作为子图。接下来我们考虑 的情况,也就是研究 的下界。
对于任意大小为 的集合 ,定义事件 为 的导出子图 是红色的 。对于所有大小为 的集合 ,定义事件 为 的导出子图 是蓝色的 。相应地我们构造依赖图 ,并定义 和 分别为所有事件 和 构成的集合。令 为 中和事件 在依赖图相邻的事件的数量。并定义 。类似地,我们可以定义 , 和 。那么我们有 ,, 以及 。
我们把每条边以 的概率染成红色,以 的概率染成蓝色。接着我们定义两个函数 和,使得对于任意 和 , 以及 ,其中 和 是 中的两个待定常数。
如果 满足以下的约束:
那么根据非对称洛瓦兹局部引理,存在一个染色使得所有事件 都不发生。可以验证,当 ,上述两个约束都有可行解。这就说明存在某些常数 使得 。
相似的论述能够证明 。这是目前我们知道关于 的最好的下界。
算法化洛瓦兹局部引理
我们之前讨论的洛瓦兹局部引理均是存在性的结论,即证明了概率空间中至少有一个样本点满足我们想要的条件。对于计算机科学来说,我们更加关心的是能否高效的找到这样的样本点。以 -合取范式的可满足性为例,Example 2 说明了在满足局部引理的条件下,公式 一定存在一组可满足解。能否在类似的条件下高效的找到这组解一直是理论计算机科学领域的重要问题。设 ,其中 。一个最简单的想法是不停的随机选取一组变量的赋值,直到找到那个可满足的赋值为止。容易看到,如果赋值满足合取范式的概率为 ,这个方法就可以在期望多项式的时间内找到可满足的赋值。但实际上,存在满足局部引理的公式,使得一个均匀随机的赋值满足该公式的概率是指数小的,因此,这个简单的采样算法不是一个高效的算法。
在 2009 年的一个突破性工作中,R. Moser (Moser (2009) ) 给出了一个十分简单算法,并成功证明了这个算法在期望线性的时间内就可以找到一组可满足解。相比于直接对全部变量进行重新赋值,该算法考虑只对没被满足的子句上的变量进行重新赋值。
Moser, Robin A. 2009. “A Constructive Proof of the Lovász Local Lemma.” In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, 343–50.
- 先在变量 上随机生成一组赋值;
- 选取在该组赋值下未满足的子句中下标最小的子句 ,调用子程序 。
- 对 中包含的变量进行重新采样赋值;
- while (存在一个子句 未被满足)
选取最小的下标 ;
调用 ;
end while
这个算法被称作 Moser’s fix 算法。他证明了在满足类似洛瓦兹局部引理的条件下,也即 ( 为依赖图的最大度数,也即每个子句除自身外所能相关的子句的最大数目),期望意义上只需要调用 次 子程序就会停止。
算法分析的大致想法如下:首先,我们注意到算法的运行过程可以被高效的编码。其次,我们可以通过算法的运行过程的编码还原出这个随机算法每一步使用的随机数。因此算法运行的越久,我们就能够得到越高效的一个对于随机数的编码方案。但是,下面定理保证,随机数串是不存在高效又正确的编码方案的,因此,算法的运行时间一定有一个上界。
Theorem 3 设 是一个对长度为 的 串的编码(即 的单射)。对任何 ,定义 为所有被编码为长度不超过 的串的集合。那么对于一个均匀随机的 有
对于该算法,我们首先有以下观察:
Proposition 1 从子程序 返回主程序 时, 执行前被满足的子句仍保持满足。
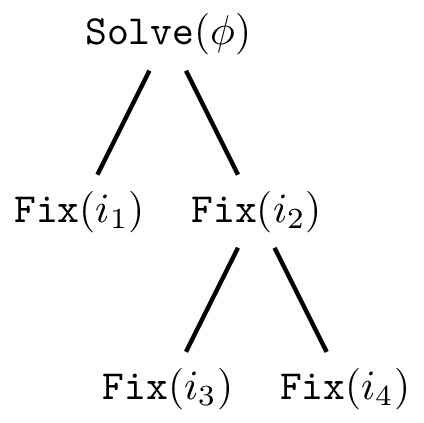
我们可以将算法的调用过程对应到按照某种规则生成的随机树结构,如 Figure 1 所示。该示例描述了算法的运行过程:在我们调用 后,我们发现 并没有满足,因此我们调用 。在该子程序中,我们对 进行重新赋值并且其自身及相关的子句都在这次赋值后得到满足。然后我们回到上一层,发现 未满足,我们调用 。在对 的变量重新赋值后,我们发现 未满足,因此我们调用 。以此类推,直到算法回到递归的起点,并且所有子句都被满足。
假定我们知道子程序 被调用了 次,那么我们知道程序总共使用了 个随机的比特。我们断言,利用树结构的信息,我们可以使用不超过 长的 串对这 长的随机 串进行编码。换言之,我们通过记录树的结构和少量额外的信息,可以恢复出算法运行过程中的随机数。
具体来说,我们用 个随机数表示算法运行 步后变量的赋值;另外的 个随机数用于表示树的结构。我们使用类似树的先序遍历的方式对树结构进行编码,具体如下:
根据 Proposition 1,我们知道每次回到 时,初始赋值下不满足的子句并不会被破坏其满足性,因此我们可以使用 个随机数来表示起始赋值中每个子句是否被满足,也即记录根节点的孩子;
对于树中的每个节点 (除根节点 ),由于他的孩子节点修改的子句是当前节点处理的子句的邻居或自身且 ,我们可以使用 个随机数来表示递归进入的是 中的哪个子句。同时,我们用一个额外的比特来表示当前结点在先序遍历中是进栈还是出栈。
由于根结点 的孩子被 个随机数表示,所以用于对内部节点编码的随机数的数量不超过。因此压缩用的随机数长度不超过 。对于任意一个对应算法运行过程的随机串 ,我们使用 来表示上述的编码过程。
Proposition 2 对于任意 ,存在一个函数 ,使得 。
Proof. 首先我们使用 中除了前 位的随机数来还原树结构。另外注意到在算法调用 的时候, 此时的赋值一定是使得 不满足的唯一赋值。因此,我们可以得到上一次对 中变量进行采样时候随机数是多少。如果在这一次调用 之后,某一个变量再也没有被重新采样,那它在这一次调用 时候的随机赋值被我们保存在了一开始的 个随机比特中。因此,我们能够用已有的信息唯一的确定 。
根据上述的讨论,我们知道如果算法在运行 步后仍然不停止,那么就能唯一地对应到长度为 的 串中的一个。根据 Theorem 3,这件事情发生的概率不超过。因此算法运行 步后仍不停止的概率不超过 ,也即算法在期望意义下只会调用 次。