第三讲:事件的条件概率
上节课我们介绍了概率空间 \((\Omega,\@F,\bb P)\) 的定义,以及它们需要满足的公理。很多关于概率空间的一些性质和操作,都可以解释成集合上对应的性质和操作。我们今天继续介绍一些性质,它们同样可以看成集合的性质,但本身也有很丰富的概率含义。可以看到,在实际应用中,我们实际思考的对象是这些集合后面的概率。
条件概率及性质
我们前面介绍过,概率空间,以及相关的记号,都是为了抽象出我们在日常做概率试验的时候的一些直观的事情。对于扔两个骰子的问题,我们可以问,在已知两个骰子的和是偶数的情况下,第一个骰子是 \(6\) 的概率。经验告诉我们,这个概率应该是用“第一个是 \(6\) 并且和为偶数”的概率,除上“和为偶数的概率”。数学上,我们把这个称之为条件概率,是定义在两个事件 \(A\) 和 \(B\) 上,用来表示在已知 \(B\) 发生的情况下 \(A\) 发生的概率。我们用记号 \(\bb P\tp{A\mid B}\) 来表示,它仅在 \(\bb P(B)>0\) 的时候有定义。
Definition 1 (事件的条件期望) \[ \bb P(A | B) = \frac{\bb P(A\cap B)}{\bb P(B)}. \]
注意到这个是条件概率的定义式,我们可以把它写成 \[ \bb P(A\cap B) = \bb P(B)\cdot \bb P(A|B). \] 这个形式可以更方便的把它想象成“事件 \(A\) 和 \(B\) 同时发生的概率,等于 \(B\) 发生的概率,乘上在已知 \(B\) 发生的时候 \(A\) 发生的概率”。
对于 \(n\) 个事件 \(A_1,\dots,A_n\),我们不停地使用上式,可以得到 \[ \bb P\tp{\bigcap_{i=1}^n A_i} = \prod_{k=1}^n \bb P\tp{A_k\mid \bigcap_{i=1}^{k-1}A_i}. \] 这个式子被称之为条件概率的链式法则。他可以读作
如果我们想计算 \(n\) 个事件同时发生的概率,我们先用第一个事件发生的概率,乘上在第一个事件发生的情况下第二个事件发生的概率,再乘上在第一第二个事件都发生的情况下,第三个事件发生的概率,…
我们可以通过一些简单的例子来验证我们对于这个概念的理解。
Example 1 假设我有正好两个孩子,其中至少一个是女孩,那么两个都是女孩的概率是多大?
在计算一个概率问题的时候,总是要先对概率空间进行合适的建模。这个问题的概率空间我们可以取样本空间为四元组 \(\Omega=\set{FF,FM,MF,MM}\),表示孩子四种性别可能,\(\@F = 2^\Omega\),\(\bb P\) 则为均匀分布。其中事件 \(B\defeq \mbox{“至少一个是女孩”}=\set{FF,FM,MF}\);事件 \(A\defeq \mbox{“两个都是女孩”}=\set{FF}\)。所以 \[ \bb P(A|B) = \frac{\bb P(A\cap B)}{\bb P(B)} = \frac{\bb P(\set{FF})}{\bb P(\set{MF,FM,FF})}=\frac{1/4}{3/4} = \frac{1}{3}. \]
Example 2 假设面前有三个抽屉,每个抽屉里有两块硬币,分别是“金币+金币”,“金币+银币”,“银币+银币”。现在我随机选一个抽屉,并且随机在这个抽屉里选一个硬币,请问在选出的硬币是金币的情况下,和选出的硬币同一个抽屉的另一个也是金币的概率是多大?
在这个问题里,我们可以用 \(\Omega=\set{一,二,三}\times \set{1,2}\),\(\@F=2^\Omega\),\(\bb P\) 为均匀分布来进行建模。对于样本点 \((i,j)\),我们想表达的意思是选出来的硬币是第 \(i\) 个抽屉里的第 \(j\) 个硬币(硬币的顺序就按照题干里说的那般)。那么定义事件 \[ \begin{align*} B &= \mbox{“选出的硬币是金币”}=\set{(一,1),(一,2),(二,1)};\\ A &= \mbox{“和选出的硬币同一个抽屉的另一个也是金币”} = \set{(一,1),(一,2),(二,2)}. \end{align*} \] 因此,我们有 \[ \bb P(A|B) = \frac{\bb P(A\cap B)}{\bb P(B)} = \frac{1/3}{1/2} = \frac{2}{3}. \]
独立性
如果对于事件 \(A\) 和 \(B\),我们有 \(\bb P(A\cap B) = \bb P(A)\cdot \bb P(B)\),或者等价的 \(\bb P(A|B) = \bb P(A)\),我们就称 \(A\) 和 \(B\) 是独立的,有时候会记作 \(A\perp B\)。直观上,事件 \(A\) 和 \(B\) 独立表示 \(A\) 或者 \(B\) 是否发生,对于对方是否发生没有影响。比如我们扔两次骰子,\(A\) 为事件“第一次扔的是 \(3\) ”, \(B\) 为事件“第二次扔的是 \(4\) ”,则这两件事情是独立的。独立性,我认为,是一个非常具有概率风味的概念。尽管到目前为止,如果 \(\Omega\) 是有限集,我们之前说过,所有的这些概率都可以用组合计数来研究,但独立性提供的直观,用计数的语言来说,并不是特别方便。
我们可以把独立的概念推广到更多的事件上去。我们说事件 \(A_1,A_2,\dots,A_n\) 是相互独立(mutually independent) 的,如果其满足对于任意的 \(I\subseteq [n]\), \[ \bb P\tp{\bigcap_{i\in I} A_i} = \prod_{i\in I} \bb P(A_i). \] 这个定义看起来非常强,因为它要求上述等式对于每一个 \(I\subseteq [n]\) 都成立。
Remark 1.
- 如果只要求 \(I=[n]\) 是不够的。假设 \(n=3\) 并且 \(A_1=A_2, A_3=\emptyset\),则 \(\bb P(A_1\cap A_2\cap A_3)=\bb P(A_1)\bb P(A_2)\bb P(A_3)=0\)。但显然这仨不一定独立。事实上,我们可以把独立的定义写成 \[ \bb P\tp{\bigcap_{i=1}^n B_i} = \prod_{i=1}^n \bb P(B_i), \] 其中 \(B_i=A_i\) 或者 \(\Omega\) 。
- 如果只要求等式对于 \(I\in\binom{[n]}{2}\) 成立是不够的。一个经典的例子是概率空间为 \(\Omega=\set{HH,HT,TH,TT}\) 上的均匀分布,即投两次均匀硬币的结果(H=Head,T=Tail)。我们考虑 \(A_1=“第一次硬币出H”\),\(A_2=“第二次硬币出H”\),\(A_3=“两次硬币结果不一样”\)。可以验证,这三个事件对于任何 \(I\in\binom{[3]}{2}\) ,是满足独立性定义的等式的,但对于 \(I=[3]\) 并不满足。实际上,如果该等式仅对于 \(I\in\binom{[n]}{2}\) 成立,我们称 \(A_1,\dots,A_n\) 是两两独立(pairwise independent) 的。这是一个在计算机科学里很重要的概念,原因在于,我们在设计算法的时候,独立的随机数本身是一个重要的资源,我们需要代价才能够产生它们。而很多问题里,对于独立的要求并没有像定义那么强,有的时候两两独立就足够满足我们的要求了。而生成两两独立的随机数,代价要小很多。
对于无穷多个事件 \(\set{A_j}_{j\in J}\),我们说它们相互独立,但且仅当对于 \(J\) 的任何一个有限子集 \(I\),\(\set{A_i}_{i\in I}\) 相互独立。
全概率公式
假设事件 \(B_1,B_2,\dots,B_n,\dots \in \@F\) 构成了样本空间的一个分划,即 \(\Omega = \bigcup_{i\ge 1} B_i\) 并且对于 \(i\ne j\), \(B_i\cap B_j=\emptyset\) 。根据集合论的知识我们知道,对于任何集合 \(A\),\(A\cap B_1, A\cap B_2,\dots,A\cap B_n,\dots\) 也构成了 \(A\) 的一个分划。如果我们取 \(A\in \@F\),则根据概率论的公理,我们有 \[ \bb P(A) = \bb P\tp{\bigcup_{n\ge 1}(A\cap B_n)} = \sum_{n\ge 1} \bb P(A\cap B_n). \] 这便是全概率公式(Law of total probability)。我们可以把 \(P(A\cap B_n)\) 用条件概率写出来,即 \[ \bb P(A) = \sum_{n\ge 1} \bb P(B_n)\cdot \bb P(A|B_n). \] 用人话说,就是想算 \(A\) 的概率,可以先按照 \(B_n\) 的情况进行分类再全部加起来,而每一类的概率是 \(B_n\) 发生的概率乘上在 \(B_n\) 发生的情况下 \(A\) 发生的概率。
一些例子
我们接下来使用上述工具,来计算一些例子。
Example 3 (抗原检测) 假设人群中感染新冠的概率是 \(0.2\%\) ,而抗原检测的准确性是 \(99\%\)。现在你做了个检测发现阳了,那真的感染新冠的概率是多大?
这个问题的结论有时候会产生一些悖论。因为看起来抗原检测的准确性非常高,因此如果检测阳性,那应该大概率真的被感染了。但通过计算我们会发现不然。
首先我们用概率空间来进行建模。我们假设人群有 \(N\) 个人,因此样本空间可以取 \(\Omega = [N]\times \set{\pm 1}\times \set{\pm 1}\)。这里的每一个三元组 \((a,i,j)\),其中 \(a\) 表示人的 id, \(i\) 表示是否被感染,\(j\) 表示是否抗原阳性。可以思考一下,我们如何设置 \(\bb P\) 来满足题设的要求,这总是可以做到的。
我们来计算在已知抗原阳性的情况下,没有被感染的概率 \(\bb P(没感染|阳性)\)。我们使用条件概率的定义,有 \[ \bb P(没感染|阳性) = \frac{\bb P(没感染 \cap 阳性)}{\bb P(阳性)}. \] 我们希望把这个分式上下都写成我们题设里告诉能算的东西,因此需要用我们之前介绍的公式来改写一下。对于分子,我们有 \[ \bb P(没感染\cap 阳性) = \bb P(阳性 | 没感染)\cdot \bb P(没感染). \] 而对于分母,我们使用全概率公式,有 \[ \begin{align*} \bb P(阳性) &= \bb P(阳性\cap 感染) + \bb P(阳性\cap 没感染)\\ &= \bb P(阳性|感染)\cdot \bb P(感染)+\bb P(阳性|没感染)\cdot \bb P(没感染). \end{align*} \] 这样一番操作之后,我们会发现每一个量我们都会计算了,即 \[ \begin{align*} \bb P(阳性 | 没感染) &= 1\%, \bb P(没感染) =99.8\%,\\ \bb P(阳性|感染) &= 99\%, \bb P(感染) = 0.2\%,\\ \end{align*} \] 把这些数字代进去,我们可以得到 \[ \bb P(没感染|阳性)\approx 83.4\%. \] 也就是说,没事去测个抗原,即使阳性了,大概八成概率也没有被感染。
上面这个计算过程有时候也被称为贝叶斯公式(Bayes’ formula)。
Example 4 (双胞胎) 双胞胎有两种,同卵双生和异卵双生。一家医院想知道所有双胞胎中同卵双生的比例有多大,但是做这个检测的成本太高了。统计学家说,其实你只要统计一下每一对双胞胎的性别,就能推算出这个比例。我们知道,同卵双生子的性别一定是一样的,而异卵双生子的性别是独立的。因此,使用全概率公式,我们有 \[ \begin{align*} \bb P(同性) &= \bb P(同性|同卵)\cdot \bb P(同卵) + \bb P(同性|异卵)\cdot \bb P(异卵)\\ &=1\cdot \bb P(同卵)+0.5\cdot (1-\bb P(同卵)). \end{align*} \] 因此,我们只要简单的统计出 \(\bb P(同性)\),即所有双胞胎中同性别的比例,便可以用上面的公式解出双胞胎中同卵双生的比例。
Example 5 (无限悖论) 假设我们有可数无穷个球,用 \(k=1,2,\dots\) 来编号,并且有一个无限大的箱子。我们考察一个“放球”与“拿球”的过程。首先是放球:在12点前1分钟,我们把 \(1,2,\dots,10\) 号球放进去;在12点前 \(\frac{1}{2}\) 分钟,我们把 \(11,12,\dots,20\) 号球放进去;在12点前 \(\frac{1}{4}\) 分钟,我们把 \(21,22,\dots,30\) 号球放进去,以此类推。对于 \(n=0,1,2,\dots\),我们在12点前 \(2^{-n}\) 分钟把 \(10n+1, 10n+2,\dots,10(n+1)\) 号球放进去。
然后我们再使用不同的方式把球拿出来。
对于 \(n=0,1,2\dots\),我们在12点前 \(2^{-n}\) 分钟放完球后,把第 \(10(n+1)\) 号球拿出来。
我们假设放球和拿球都是瞬时完成的,我们来计算一下,在 \(12\) 点的时候,箱子里有多少个球。显然,这种情况下箱子里会有无穷多个球,因为所有编号不是10的倍数的球都被放了进去并且没有被拿出来。
我们换另外一种拿球的方式。
对于 \(n=0,1,2\dots\),我们在12点前 \(2^{-n}\) 分钟放完球后,把第 \((n+1)\) 号球拿出来。
使用这种拿球的策略,在 \(12\) 点的时候,箱子里有多少个球呢?一番思考之后,不难发现,箱子里一个球都没有!因为对于每一个 \(k\in \bb N\),第 \(k\) 号球在 \(n=k-1\) 的时候被拿出来了。
和第一种情况一样,每次都是只拿了一个球出来,居然产生的结果截然不同。我现在想问,如果我随机的选一个球出来,又当如何呢?
对于 \(n=0,1,2\dots\),我们在12点前 \(2^{-n}\) 分钟放完球后,我们从箱子里均匀随机的拿一个球出来。
我们来计算每一个球在 12 点的时候留在箱子里的概率。我们这儿以1号球为例,其它的球的计算方式类似。对于每一个 \(n=0,1,2,\dots\),我们用事件 \(A_n\) 来表示在第 \(n\) 轮操作之后(即12点前 \(2^{-n}\) 分钟放球拿球的操作完成之后),1号球还在箱子里这个事件。我们关注的是事件 \[ A_\infty \defeq \bigcap_{n\ge 0} A_n = \lim_{n\to\infty} A_n \] 发生的概率。根据我们上一节课介绍的概率测度的连续性,我们有 \(\bb P(\lim_{n\to\infty} A_n) = \lim_{n\to\infty}\bb P(A_n)\)。因此,我们只需要计算 \(\bb P(A_n)\),第 \(n\) 轮结束后1号球在箱子里的概率。对于 \(n=0,1,\dots\),我们再定义一个事件 \(B_n\),用来表示,在第 \(n\) 轮的时候拿出的球不是1号球,则有 \(A_n = B_0\cap B_1\cap\dots\cap B_n\). 使用条件概率的链式法则,我们可以得到 \[ \bb P(A_n) = \bb P\tp{\bigcap_{i=1}^n B_i} = \prod_{k=0}^n\bb P\tp{B_k\mid\bigcap_{i<k} B_i}. \] 我们把 \(\bb P(A_n)\) 写成这样的目的是因为对于每一个 \(k=0,1,\dots,n\),条件概率 \(\bb P\tp{B_k\mid\bigcap_{i<k} B_i}\) 有着自然的组合意义,并非常好计算:在 \(\bigcap_{i<k} B_i\) 的条件下,这对应于箱子里有 \(9(k+1)+1\) 个球,其中一个是1号球,我们拿了一个球,但它不是1号球的概率。显然,这个概率是 \(1-\frac{1}{9(k+1)+1}\)。所以,我们有 \[ \bb P(A_n) = \prod_{k=0}^n \tp{1-\frac{1}{9(k+1)+1}}\le e^{-\sum_{k=0}^n \frac{1}{9k+10}}. \] 我们知道级数 \(\sum_{k=0}^n \frac{1}{9k+10}\) 是发散的,因此,\(\lim_{n\to\infty} \bb P(A_n)=0\)。
所以,我们知道了,在12点的时候,1号球在箱子里的概率是0。我们用 \(S_i\) 来表示第 \(i\) 号球在12点的时候还在箱子里的概率。我们刚才计算得知 \(\bb P(S_1)=0\)。可以使用类似的方法,我们能够得到对于任意 \(n\in \bb N\), \(\bb P(S_n)=0\)。我们现在关心的是在12点的时候箱子里有球的概率,即 \(\bb P(\exists n\in\bb N, S_n)\)。我们使用上节课讲过的 union-bound,可以得到 \[ \bb P(\exists n\in\bb N, S_n)\le \sum_{n\ge 1} \bb P(S_n) = 0. \]
Example 6 (Karger 的最小割算法) 我们来看一个经典的算法问题,求图上的最小割。给定一个连通无向图 \(G(V,E)\),我们说一个边集 \(C\subseteq E\) 是一个割,当且仅当把 \(C\) 从图中删掉之后,得到的图 \(G(V,E\setminus C)\) 是不连通的。最小割问题即寻找图上最小的一个割。
学过算法的同学都知道,我们可以用最大流的方法来寻找最小割:固定一个源 \(s\) 并枚举所有可能的汇 \(t\),对每一个源-汇对 \((s,t)\) 求解最大流,其残量网络(residual network)给出了最小割。使用2022年最快的最大流算法,我们需要 \(nm^{1+o(1)}\) 的时间来寻找这个最小割,其中 \(n=\abs{V}\),\(m=\abs{E}\)。我们来介绍一个随机算法,实现非常简单,并且在有效的优化之后比基于最大流的算法要更快。
我们定义图上的所谓缩边(contraction) 的操作。给定边 \(e=\set{u,v}\in E\) ,我们缩掉 \(e\) 的操作指的是把 \(u\) 和 \(v\) 合并成一个点,并且删掉之前所有 \(u\) 与 \(v\) 之间的边(他们俩与别的点相连的边依然保留)。我们把缩完之后的图记作 \(G/e\)。如下图所示,我们缩掉了边 \(\set{1,2}\)。
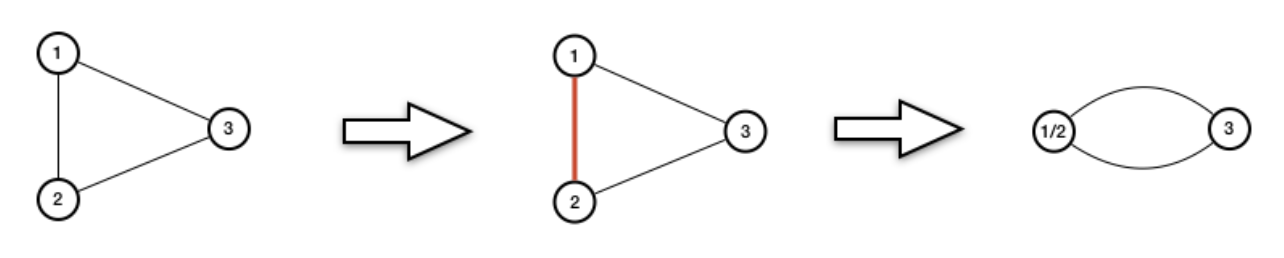
Karger算法非常简单,从 \(G\) 出发,每一次随机选择一条边,把它缩掉。重复执行 \(n-2\) 次之后,图中只剩两个点了,然后输出所有剩下的边。
while G contains more than two vertices do
Choose an edge e uniformly at random
Contract e in G
return remaining edges这个算法“有可能”成功的原因也很简单,由于我们关心的是“最小的”割,那么算法的每一步,选到割中的边的概率都不会太大。当然了,要谈论这个概率,我们需要有合适的概率空间。一个自然的样本空间可以是算法执行过程中所有(有序的)删除的边的序列。我们可以在上面定义合适的概率测度。
我们设 \(C\) 是一个固定的最小割,并且其大小是 \(k\)。我们来计算算法最终输出 \(C\) 的概率。很容易发现,算法最终输出 \(C\) ,当且仅当算法执行 while 的循环中,每一次都没有选到 \(C\) 中的边。因此,我们用 \(A_k\) 来表示上面代码里面第 \(k\) 次执行完 while 循环之后,还没有删过任何一个 \(C\) 中边的这个事件。为了分析 \(\bb P(A_k)\) ,我们对于每一个 \(k=1,2,\dots,n-2\),定义事件 \(B_k\) 为“第 \(k\) 次 while 循环选择的不是 \(C\) 中边”这一事件。那么显然有 \(A_k=\bigcap_{i=1}^k B_i\)。因此,由条件概率的链式法则, \[ \bb P(算法输出C)=\bb P(A_{n-2}) = \prod_{i=1}^{n-2} \bb P\tp{B_i\mid \bigcap_{j=1}^{i-1} B_j}. \] 我们希望给上述概率一个下界,即每一轮均有比较大的概率不选到 \(C\) 中的边。由于我们每一轮是均匀的选, 因此我们只需要证明,对于第 \(i\) 轮,在已知 \(\bigcap_{j=1}^{i-1} B_j\),即前 \(i-1\) 轮均没有选到 \(C\) 中边的情况下,图中剩余的边足够多即可。一个最重要的观察是 > 此时,图中每一个顶点的度数均不少于 \(k\)。
这件事情成立的原因是,如果有一个顶点的度数 \(<k\),那么在当前的图中,这个顶点与其邻居相连的边,构成了该图中的一个割。同时,也不难发现,这个割也一定是原图 \(G\) 中的一个割(因为收缩这种操作不会破坏它是割的性质)。但这就说明,我们找到了一个大小比 \(k\) 更小的割,这与我们假设 \(C\) 是最小的割矛盾。
有了这个观察,因为我们知道算法在第 \(i-1\) 轮后,还剩余 \(n-i+1\) 个顶点。所以第 \(i\) 轮开始的时候,图中至少还有 \(\frac{k}{2}\cdot (n-i+1)\) 条边。于是,我们有 \[ \bb P\tp{B_i\mid \bigcap_{j=1}^{i-1} B_j} \ge 1-\frac{2k}{k(n-i+1)} = \frac{n-i-1}{n-i+1}. \] 这说明, \[ \bb P(A_{n-2}) \ge \prod_{i=1}^{n-2} \frac{n-i-1}{n-i+1} = \frac{2}{n(n-1)}. \] 因此,我们的算法有 \(\frac{2}{n(n-1)}\) 的概率能够输出最小割 \(C\)。我们可以重复这个算法 \(N=50n(n-1)\) 次,并且输出这 \(N\) 次中找到最小的那个割。那么,这个割是最小割的概率至少有 \[ 1-\tp{1-\frac{2}{n(n-1)}}^{N}\ge 1-e^{-100}. \]
最后我们来计算一下算法的复杂性。我们要重复算法 \(N=O(n^2)\) 次,每一次要进行 \(n-2\) 次收缩操作。如果我们使用并查集来维护的话,大约需要一共需要 \(\tilde O(n^2m)\) 的时间。这个时间是比前文提到的使用最大流的算法要慢的(都怪最大流算法发展的太快了,上一次讲的时候最大流还要 \(\tilde O(nm)\) 呢),但好处在于实现非常简单。事实上,Karger 算法可以进一步改进,使得只需要 \(\tilde O(n^2)\) 的时间即可。我们把这个改进留为作业。